Introduction to AWS S3
AWS S3 is a highly scalable, durable, and secure object storage service, making it an ideal choice for managing large-scale workflows like those in Nextflow. Nextflow includes built-in support for AWS S3, allowing seamless integration of S3 buckets into pipeline scripts. Files stored in an S3 bucket can be accessed transparently in your pipeline script, just like any other file in the local file system, enabling efficient data management across cloud and on-premises environments.
Pre-requisites for Using S3 with Nextflow
Before you begin, ensure you meet the following prerequisites:
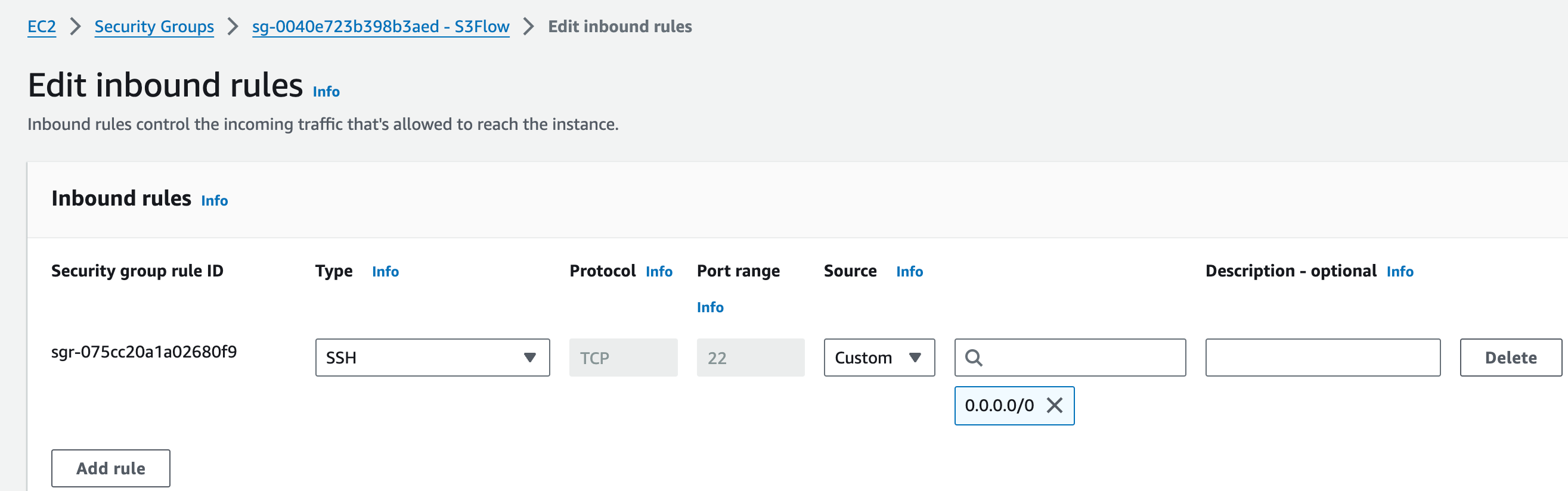
1. A VPC Security Group with an Inbound Rule for Port 22
Ensure that your virtual private cloud (VPC) is properly configured to allow SSH access to the instances running your Nextflow pipelines. This requires a security group with an inbound rule to allow connections on port 22, which is used for SSH.
Navigation: AWS EC2 console -> Network & Security -> Security Groups
2. Create a New S3 Bucket for Storing Nextflow Output and Workdir Files
To store the outputs of your Nextflow pipelines and the intermediate files created in the Nextflow workdir, you will need a dedicated S3 bucket. This S3 bucket will serve as both the working directory and the final storage location, ensuring that all files generated during the pipeline's execution are accessible for future reference or further processing.
To create a new S3 bucket, follow these steps:
- Navigate to the AWS S3 Console.
- Click on Create Bucket to begin the setup process.

- After the bucket is created, you need to create two folders within the bucket: one for the output files and one for the workdir.

- You can then select each folder by checking the box next to it, and click on Copy S3 URL to obtain the folder's URL. This URL will be required for configuration in the upcoming
Editing the Configuration Filesection.

3. Prepare All Required Scripts
- s3flow_persistent_hostinit.sh
curl -O https://mmce-data.s3.amazonaws.com/s3flow/v1/s3flow_persistent_hostinit.sh- keep_alive.sh
The content ofkeep_alive.shis as follows:
#!/bin/bash
# Keep the script running indefinitely
while true; do
sleep infinity # This ensures the script never stops
doneIt is recommended to keep these three files in the same folder. Ensure that the EC2 Instance or local machine where these files reside has float installed.
Deployment Steps for Individual Users on MMCloud
Float Login
Ensure you are using the latest version of the float CLI:
sudo float release syncLogin to your MMCloud OpCenter:
float login -a <opcenter-ip-address> -u <user>After entering your password, verify that you see Login succeeded!
Float Secret
Set your AWS credentials as secrets in float:
float secret set AWS_BUCKET_ACCESS_KEY <BUCKET_ACCESS_KEY>
float secret set AWS_BUCKET_SECRET_KEY <BUCKET_SECRET_KEY>To verify the secrets:
float secret lsExpected Output:
+-------------------------+
| NAME |
+-------------------------+
| AWS_BUCKET_ACCESS_KEY |
| AWS_BUCKET_SECRET_KEY |
+-------------------------+Deploy Nextflow Head Node
Deploy the Nextflow head node using the nextflow:jfs template:
float submit -i nextflow:jfs \
--hostInit s3flow_persistent_hostinit.sh \
--storage <S3_bucket_name_of_user_input_data > \
--vmPolicy '[onDemand=true]' \
--migratePolicy '[disable=true]' \
--securityGroup sg-XXXXXXXX \
-c 2 -m 4 \
-n <head-node-name> \
-j keep_alive.shNote:
- Replace
<head-node-name>and<security-group>with your specific details. We recommend starting<head-node-name>withS3FLOW_PERSISTENT_HEAD_XXXfor better understanding purposes. - The nextflow:jfs template comes pre-configured with S3 setup.
-c 2 -m 4is used to specify the head node’s CPU and memory configuration. Below, you will also see an example of modifying the nextflow:jfs template using the--overwriteTemplate "*" -c 8 -m 32command to change the head node’s CPU and memory settings.- Using --storage is not mandatory, but it can be beneficial for certain users. For more details, please refer to the FAQ section of this tutorial.
Overriding Template Defaults if Needed
Customizing CPU and Memory
To override default CPU and memory settings:
--overwriteTemplate "*" -c <number-of-cpus> -m <memory-in-gb>Example: To set 8 CPUs and 32GB memory:
--overwriteTemplate "*" -c 8 -m 32Specifying a Subnet
For deploying in a specific AWS subnet:
--overwriteTemplate "*" --subnet <SUBNET-ID>Mounting S3 Buckets as Data Volumes
You can mount the input data bucket using S3FS as a data volume on the Nextflow head node and worker nodes as follows:
--dataVolume [mode=r,accesskey=xxx,secret=xxx,endpoint=s3.REGION.amazonaws.com]s3://BUCKET_NAME:/staged-filesIncremental Snapshot Feature (From v2.4)
Enables faster checkpointing and requires larger storage:
--overwriteTemplate "*" --dumpMode incrementalChecking Head Node Deployment Status
float list -f 'status=executing'Example Output:
+-----------------------+--------------------------+-------------------------------+-------+-----------+----------+----------------------+------------+
| ID | NAME | WORKING HOST | USER | STATUS | DURATION | SUBMIT TIME | COST |
+-----------------------+--------------------------+-------------------------------+-------+-----------+----------+----------------------+------------+
| n0ez2czrqmw2kp67tstmk | S3FLOW_PERSISTENT_HEAD_1 | 3.80.52.8 (2Core4GB/OnDemand) | admin | Executing | 29m51s | 2024-10-10T22:31:21Z | 0.0210 USD |
+-----------------------+--------------------------+-------------------------------+-------+-----------+----------+----------------------+------------+Get SSH key via float command
- Locate the public IP address of the head node in the Working Host column.
- Retrieve the SSH key from Float's secret manager:
float secret get <job-id>_SSHKEY > <head-node-name>-ssh.keySee the screenshot below as an example:

- Note: If you encounter a
Resource not founderror, wait a few more minutes for the head node and SSH key to initialize.
- Set the appropriate permissions for the SSH key:
chmod 600 <head-node-name>-ssh.keySSH to S3Flow Persistent Head Node
SSH into thehead node using the provided SSH key, username, and the head node's public IP address:
ssh -i <head-node-name>-ssh.key nextflow@<head-node-public-ip-address>See the screenshot below as an example:

- Note: Use the username
nextflowto log in as an admin.
MMC NF-Float Configuration
Editing the Configuration File
- Copy the template and edit the configuration file:
cp mmcloud.config.template mmc-s3flow.config
vi mmc-s3flow.config- Note: If you are new to using
vi, check out this [Beginner's Guide to Vi](https://www.howtoge ek.com/102468/a-beginners-guide-to-editing-text-files-with-vi/) for basic instructions.
If you're not comfortable using vi to modify config files, you can follow the "Accessing via VSCode" section at the end of this tutorial to SSH into the head node
- The mmc-s3flow.config file copied from the
mmcloud.config.templatewill be pre-filled with the OpCenter IP address and the PRIVATE IP address of the Nextflow head node. You only need to provide your OpCenter username, password, and AWS access, secret keys and region in the config.
Configuration File Content:
plugins {
id 'nf-float'
}
workDir = 's3://<your_s3_bucket_name/your_workDir_folder_name/'
process {
executor = 'float'
errorStrategy = 'retry'
/*
If users would like to enable float storage function, specify like this
extra = '--storage <S3_bucket_name>'
*/
/*
If extra disk space needed, specify like this
disk = '200 GB'
*/
extra = ''
/*
For some special tasks like Qualimap, which generates very small IO requests, using this -o writeback_cache can help with performance. Here's an example:
withName: "QUALIMAP_RNASEQ" {
extra = ''
}
*/
}
podman.registry = 'quay.io'
float {
address = '<your_opcenter_ip>'
username = '<your_user_name>'
password = '<your_password>'
}
// AWS access info if needed
aws {
client {
endpoint = 'https://s3.<your_bucket_region>.amazonaws.com'
maxConnections = 20
connectionTimeout = 300000
}
accessKey = '<bucket_access_key>'
secretKey = '<bucket_secret_key>'
region = '<bucket_region>'
}Note:
- Replace the value of
workDirwith the S3 URL of the workDir you copied earlier. - Remember to add
endpoint = 'https://s3.<your_bucket_region>.amazonaws.com'underclient. - If you are providing a bucket in
us-east-1, update the endpoint in your config file like so:aws { client { endpoint = 'https://s3.us-east-1.amazonaws.com' } }
Using Tmux
Start a tmux session named nextflow:
tmux new -s nextflowTo attach to an existing tmux session:
tmux attach -t nextflow- Tip: If you are new to
tmux, here is a handy Tmux Cheat Sheet.
Nextflow Version Check
Check the Nextflow version and update if necessary:
nextflow -vExample Output:
nextflow version 24.04.4.5917Launch Nextflow
Launch a Nextflow or nf-core/<pipeline> by providing the MMC config file:
nextflow run nf-core/<pipeline> \
-profile test \
-c mmc-s3flow.config \
--outdir s3://nextflow-work-dir/<pipeline>- Note: Replace the value of --outdir with the S3 URL of the output folder you copied earlier.
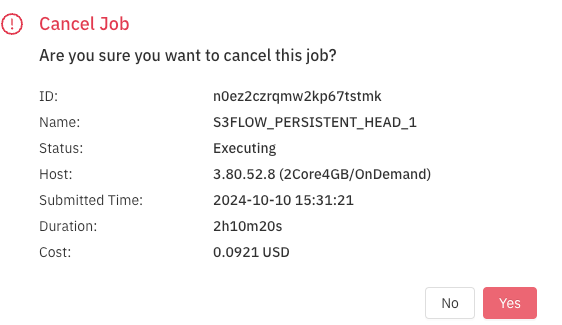
Head Node Management
In this persistent head node setup, the user is responsible for disposing of the head node. To cancel the head node job, click the cancel button for the job as shown below.

How to Use the SSH Client in VSCode
1 Install the Remote-SSH Plugin
To use the SSH client in VSCode, you first need to install the "Remote-SSH" plugin. Click the Extensions icon on the left sidebar of the VSCode interface, type Remote-SSH in the search bar, and press Enter. The plugin will appear in the search results. Click Install and wait for the installation to complete.
Figure 1: Search for the Remote-SSH plugin in the Extensions marketplace

2 Add a Remote Host
Once the plugin is installed, click the Remote Explorer icon on the left side of VSCode. In the SSH section, click the + icon to add a new host. A host refers to the SSH server you want to connect to.
Figure 2: Click the "+" to add a new host

In the input field that appears, enter the host details in the format ssh user@IP_address -A. For example, if the SSH server's IP address is 90.80.52.8 and the username is nextflow, you would enter:
ssh nextflow@ 90.80.52.8 -AFigure 3: Enter the host details

Next, you'll be prompted to choose a path to save the SSH configuration. If the specified file doesn't exist, VSCode will create a new one. If the file already exists, the new host information will be added to the beginning of the file. You can select any location for the config file, but ensure you have read and write permissions for that path. Typically, the file path would be something like C:\Users\username\.ssh\config.
Figure 4: Select the appropriate config file

After selecting the config file, you'll see a notification at the bottom right that says "Host added." Click Open Config to review the configuration file.
Figure 5: Review the config file

In the config file, you will see the following structure:
Host <host_name>
HostName <host_ip>
User <username>
ForwardAgent yes
IdentityFile "/Users/speri/memverge/s3flow/cgtpk5fhwpd3n1jva2xka_SSHKEY"Note: This IdentityFile is <head-node-name>-ssh.key, you generated earlier via command float secret get <job-id>_SSHKEY > <head-node-name>-ssh.key
Ensure the details are correct. Once confirmed, you can close the file. At this point, the host has been successfully added.
Figure 6: Verify the host details

3 Connect to the Remote Host
To connect to the remote host, click the green >< icon located at the bottom left of the VSCode window. This will open the remote connection window.
Figure 7: Open the remote connection window

After cilcking, you will see below screesnhot

4 Open and Edit Files Remotely
Once connected, you can browse the remote server's file system in VSCode. Open files and edit them directly as if they were on your local machine.
Select the host you just added from the list, and VSCode will establish an SSH connection to the remote server.

Now you can easily edit your files and templates using VSCode's remote editing features.

Creating Job Templates to Launch via MMCloud GUI
Job Templates allow you to streamline and customize runs that follow a similar format, without the need to manually configure a command for each execution. To create a job template, you must first submit a job, which you will later use to save as a template.
Steps to Create a Job Template:
-
Navigate to the Jobs Dashboard:
- After submitting a job (such as the head node job in this case), go to the Jobs section from the MMCloud GUI dashboard.
-
Select the Head Node Job:
- In the Jobs dashboard, locate and select the head node job that you previously submitted.
-
Save as Template:
- Click on More Actions (located in the top-right corner), and then choose Save as Template from the dropdown menu.

- Click on More Actions (located in the top-right corner), and then choose Save as Template from the dropdown menu.
-
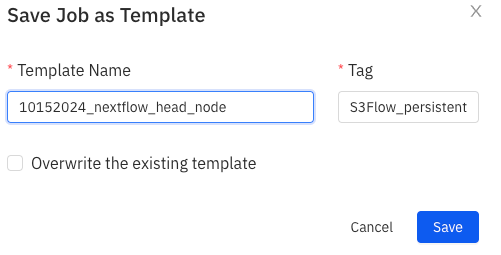
Provide Template Information:
- In the Save Job as Template dialog box, provide a name for your template under Template Name.
- Assign an appropriate Tag to easily identify the template later on (e.g., "S3Flow_persistent").
- You can optionally check the box to overwrite an existing template with the same name.
- Once done, click Save.
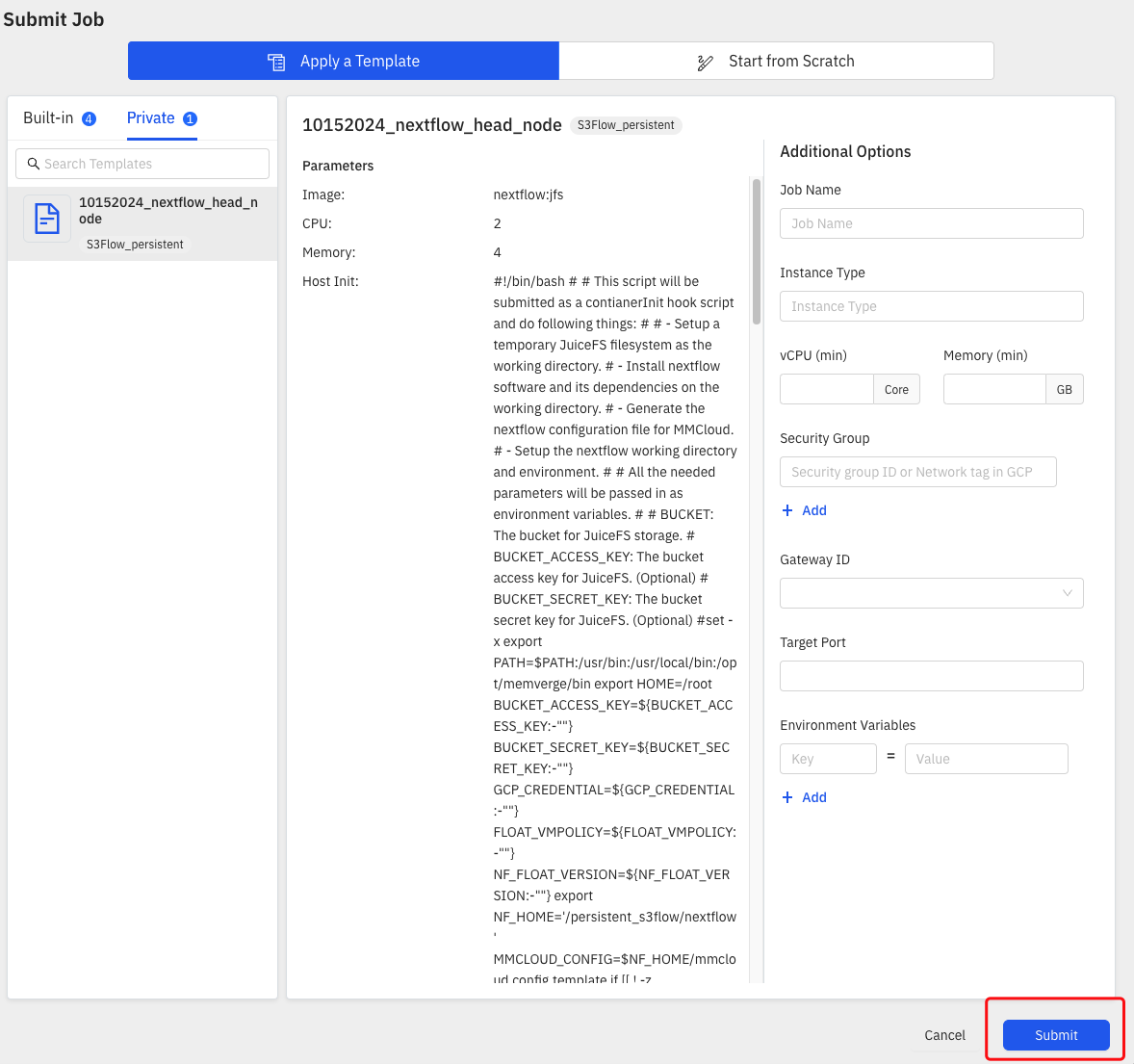
- Accessing the Saved Template:
- Navigate to the Job Templates section from the left-side menu.
- Switch to the Private templates tab to view your saved template.
- You should now see the newly saved template listed, along with its status and other details.

- Using the Job Template:
- Once the template is saved, you can use it to launch new jobs with the same configuration, saving time by avoiding repetitive setups. Simply select the template from the Job Templates dashboard and initiate the job run.
FAQ
Q: What does the --storage option do?
A: In the past, if --dataVolume or --storage wasn't used, and a user provided input files (e.g., FASTQ) using S3 URLs, Nextflow would first have to copy these files into the workDir so that the Nextflow process could access them. This step, called staging, had a significant downside: even if only a small part of a file in the S3 bucket changed, Nextflow would still need to download the entire file again into the workDir for each process.
With the introduction of --dataVolume and --storage, this staging process is no longer necessary. These options allow Nextflow to directly access files in the S3 file system, eliminating redundant file transfers. This approach uses the open-source s3fs solution, which enables seamless interaction with S3 as if it were a file system. You can find more details here: s3fs GitHub.
Additionally, the --storage option was introduced to simplify the use of --dataVolume. Previously, you had to manually provide AWS credentials when using --dataVolume, but with --storage, that’s no longer required.