
Cloud Automation 2.0 - Make EVERYTHING Serverless
Cloud’s promise unfulfilled
Recent news suggest that the growth of cloud adoption is encountering serious impedance. There are even organizations repatriating compute resources back to on-premises data centers, and cloud cost seems to be the culprit.
Indeed, a 2 CPU (24 core)/48 GB RAM server sells for ~$10,000. On AWS, a 24 vCPU / 48 GB RAM VM costs ~$1.18/hr. If you continuously ran the VM for 1 year, you would have paid $10,195 and could have bought the server hardware. Since the typical useful life of server hardware is 4–5 years, you would’ve overpaid 4–5 times for the server. Of course in a more rigorous comparison we need to consider operational costs but I think we all agree that continuously running the cloud server the same way as an on-prem server is costly.
The key word, of course, is “continuously.” To reap the benefit of the cloud you need to use it efficiently, i.e., releasing resources that you are not using, and using resources that match the needs of your applications.
Several challenges stand in the way of efficient cloud usage in the enterprise:
App owner access to the cloud
The team that manages the cloud resources, i.e., the cloud admin team, is not the team that is running the applications, i.e., the application owners: the developers, the analysts, the scientists, et al. The application users often need to wait hours or days to gain access to cloud resources, and they don’t have the tools or the discipline to release the resources as quickly as possible.
App owner flying blind
The application owners may not know the most appropriate machine size to use for their applications. Often, they do not have the tools necessary to view the resource utilization of the application. They only know their cloud bill is high, their application seems to take a long time to complete, they suffer out-of-memory errors, and their application crashes and must be restarted.
Forced to provision for peak usage
Even when the application owner understands the application, it is often difficult to pick one machine size because most applications have peaks and troughs in their resource utilizations. If one picks the machine size that can handle the peak utilization, it often means the machine is under-utilized most of the time. If one sacrifices performance by under provisioning, then the application may crash (OOM) or otherwise run very slowly.
The serverless model for complex, stateful apps
When we set out to build a product for the cloud, leveraging the fruits of our research in Big Memory Computing, we asked ourselves, “Can we build software that enable all applications, including stateful apps, to be serverless?” That means application owners can focus on their subject areas and never need to worry about management of servers or other cloud resources, nor depend on another team to do so.
Stateful applications should be able to take advantage of the elasticity of the cloud and consume resources most appropriate for it, even when the resource utilization is bursty. Serverless computing services, such as AWS Lambda, have proven that the serverless model is highly desirable for cloud native microservices. But how do we enable complex applications, even stateful applications, to run serverless?
Decoupling complex, stateful applications from servers

Application runtime is “chained” to servers
Recent news suggest that the growth of cloud adoption is encountering serious impedance. There are even organizations repatriating compute resources back to on-premises data centers, and cloud cost seems to be the culprit.
Indeed, a 2 CPU (24 core)/48 GB RAM server sells for ~$10,000. On AWS, a 24 vCPU / 48 GB RAM VM costs ~$1.18/hr. If you continuously ran the VM for 1 year, you would have paid $10,195 and could have bought the server hardware. Since the typical useful life of server hardware is 4–5 years, you would’ve overpaid 4–5 times for the server. Of course in a more rigorous comparison we need to consider operational costs but I think we all agree that continuously running the cloud server the same way as an on-prem server is costly.
The key word, of course, is “continuously.” To reap the benefit of the cloud you need to use it efficiently, i.e., releasing resources that you are not using, and using resources that match the needs of your applications.
AppCapsule technology makes it possible
We invented a solution for decoupling stateful apps from servers with AppCapsule technology. A stateful application is one whose execution depends on the data stored in memory. Because memory is not persistent, when the server hardware reboots or changes, the data in memory is lost, and the application must start from the beginning again. Our AppCapsule creates a snapshot of all the data in memory, and all the application states required to restore the application to this moment in time, as well as the data on storage. With AppCapsule, we can transport the application runtime across different machines, even different clouds.
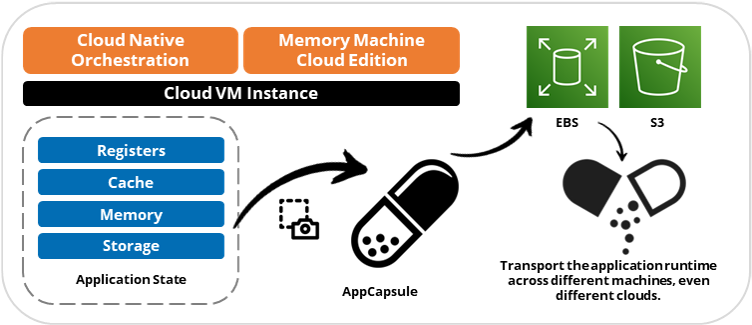
AppCapsule Snapshot
Armed with this technology, we set out to build control components that natively integrates with the clouds, and the user interface designed to serve the application users, and voilà, we have Memory Machine Cloud, the cloud automation platform that delivers the Serverless experience for most applications.
The Floating App
The internal engineering codename for Memory Machine Cloud is “Float,” because when you launch your application using Memory Machine, your application is floating on the cloud, untethered to the server it is running on. For that reason, our CLI commands all start with the keyword “float.”
It’s pretty amazing what you can do when your application is floating. The first use case we tackled was running long, stateful jobs, such as genomic sequencing, on spot instances. Spot instances offer the most economical way to tap into the vast compute resources in the public cloud, but because the CSP can evict your workload on spot with a very short notice period, they are not suitable for these jobs. That is, unless you use Memory Machine Cloud.
When you launch your genomic sequencing job using Memory Machine, you simply specify the spec of the machine, and that you want to leverage spot instances. Memory Machine takes care of finding the spot instances, deploying your containers, mapping your storage, and launching your job. If there is a spot eviction event, Memory Machine creates an AppCapsule, and moves it to another spot instance, where the job will continue. In fact, the application is unaware of the floating event. This use case alone, we have found, consistently saves our users more than 60% in compute cost.
Submitting a job with the Float GUI
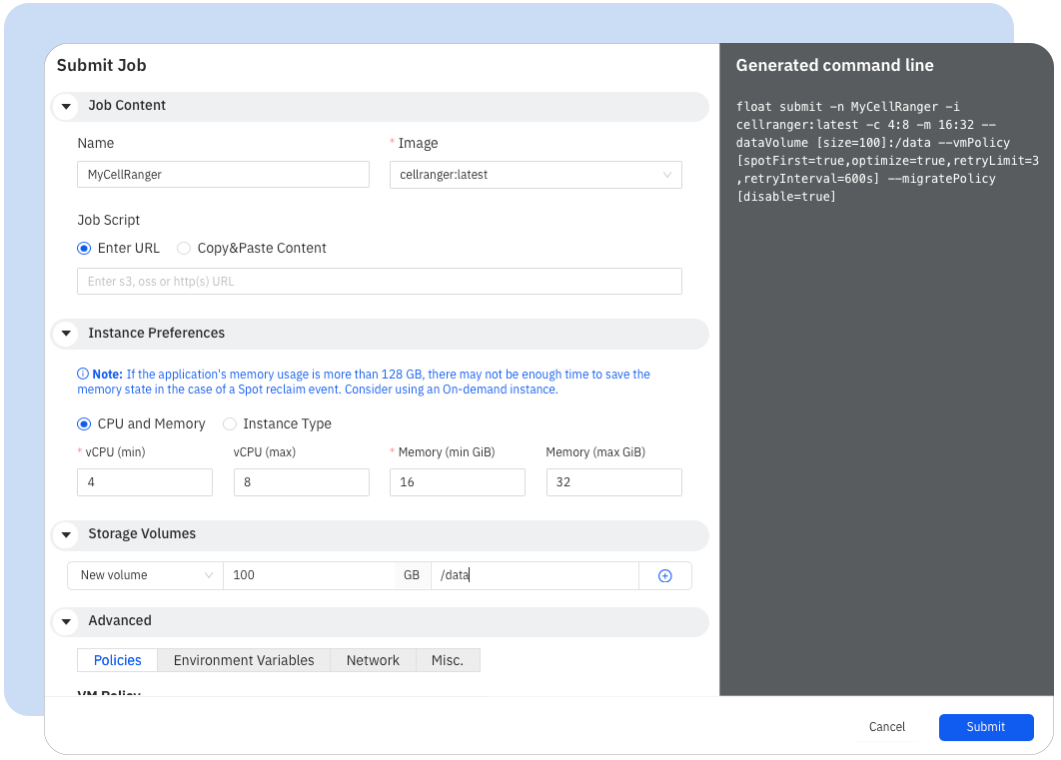
Launching your job in the Cloud takes <1 minute
Another use case is rightsizing. Often an application’s resource utilization curve has peaks and valleys over time. That is problematic for picking the appropriate machine capacity for the application. However short-lived, the peak memory usage typically becomes the minimum memory capacity for the machine, lest the application will experience an OOM and crash. That also means that during the majority of the execution, the machine is underutilized.
By making the application runtime float on the cloud VM, Memory Machine Cloud has a great solution for this problem. It constantly monitors the resource utilization of the application, and when it detects under- or over- utilization conditions, it can “float” the application to a more appropriate machine. This becomes especially handy when the user uses a workflow manager, such as NextFlow or Cromwell, to kickoff hundreds and thousands of jobs, and it is virtually impossible to manually pick the most appropriate machine types for each of the jobs.
Monitoring resource utilization and “floating” the app to a more appropriate VM

WaveWatcher shows how jobs automatically “surf” to the most appropriate instance type
The post-server era
In the hardware world, we are seeing tremendous progress in the deconstruction of servers, composable CPU, Storage, and most recently, memory. Those innovations will manifest themselves in the public cloud soon. There is a need and an opportunity to build the automation layer that enables application users and IT operators to transition into “post-server” mode TODAY, not only for cloud native applications, but for all applications. That is the mission of Memory Machine Cloud.