
Green Cloud: Computing for a Low-Carbon Future
Summary
Starting with the Fire Island release, the MMCloud Operations Center displays estimates for the carbon footprint attributable to individual jobs. This is the start of a journey to equip users with the tools to monitor (and manage), not only cost and performance, but also the carbon footprint of the jobs they submit. The initial step provides measurement and awareness; recommendations and AI-driven management follow in later releases.
Sustainability and Corporate Strategy
Sustainability is a broad term that includes environmental factors, such as carbon footprint and pollution, as well as social concerns, such as diversity and workplace safety. No longer just a buzzword, sustainability is now a key part of corporate strategy, for reasons that include:
- Investor pressure
- Consumer demand
- Regulatory compliance
- Talent acquisition
- Productivity improvement
In this blog, we focus only on carbon footprint, how it relates to IT infrastructure, and how MMCloud can help reduce the carbon footprint associated with compute cycles.
Efficiency of Hyperscale Data Centers
Data centers consume a lot of energy. A figure often-quoted (Pulse, IEA) is that data centers generate about the same amount of carbon emissions globally as the airline industry (roughly 2% of all carbon emissions) (IEA). What is obscured in this comparison is that hyperscale data centers are extremely efficient in converting energy into compute cycles. While not every compute cycle generates a social good, many do, for example, in medical research and in simulations of potential solutions to global environmental challenges. Hyperscale data centers are more efficient than privately operated data centers because hyperscale Cloud Service Providers (CSPs) keep their servers running at higher utilization levels (by a factor of two to five) and have invested heavily in optimizing their electrical distribution and cooling infrastructure.
The energy efficiency of a data center is measured by its Power Usage Effectiveness (PUE) - the ratio of the electrical power entering the data center to the electrical power used to run the IT equipment. The theoretical minimum value of PUE is one - the closer to one, the higher the efficiency. A data center in Iceland reports a PUE of 1.06 by taking advantage of geothermal steam, free air cooling, and hydroelectric power. Responses to a 2021 survey of data center operators suggest an average PUE of 1.57 in large data centers (Statista). In comparison, Google Cloud reports an average PUE of 1.10 across all data centers in 2023 (Google).
Power Consumption of a Virtual Machine
Zooming in from the energy consumption of an entire hyperscale data center to the electrical power drawn by an individual virtual machine running on a single server in that data center is not a trivial exercise (Teads). Although details vary, there is broad agreement that the power drawn by a virtual machine depends on the following factors.
- Processor in the underlying physical server
- Number of cores (virtual CPUs)
- Memory capacity
- Load
There is evidence that the power consumption also depends on the instructions executed, in other words, power consumption depends on the software application running.
Several calculators are available (some free and some for paying customers only) accompanied by data and explanations of the methodology including references to academic research. Results vary across the calculators because of different assumptions. Although work continues to improve the data, there are still input parameters (for example, server utilization) that cause wide swings in the results. The free calculators (listed below) are used extensively.
Assumes that the power draw from memory depends only on the memory allocated, not on the memory used, which argues strongly for using a virtual machine where memory utilization is close to the memory capacity. The number cited is 0.3725 W per GB.
Includes a spreadsheet listing the power draw, at different utilization levels, for a wide range of virtual machines, available from hyperscale CSPs. An idle server stills draws power (an idle big server draws more power than an idle small server). Although the power draw increases as utilization increases, it is still more efficient to run a virtual machine on a busy server. The power draw for memory is estimated to be 0.392 W per GB, slightly higher than used in the Green Algorithms calculator.
Uses the Cloud Carbon Footprint dataset. Includes information on the carbon emissions cause by manufacturing servers.
Although the calculators are slightly different, each requires the user to have knowledge of the virtual machine under consideration (either the virtual machine name or the processor, number of vCPUs, and memory capacity), server utilization, and where the server is located.
Using WaveRider to Reduce Power Consumption
For most jobs, especially in bioinformatics and machine learning, resource utilization (CPU, memory, and storage) is not constant throughout the job run. Often, the job begins with a data input stage where CPU utilization is low and memory utilization rises slowly, followed by a computational phase where both CPU and memory utilization are high. Often, the next stage involves writing results to storage – CPU utilization is low and memory utilization drops. This cycle may repeat several times.
To avoid out-of-memory errors, users size their virtual machines to accommodate the peak load, which means there are periods (they could be long) where the virtual machine is underutilized. The bigger the virtual machine, the bigger the energy drain, so unused resources are not free, either monetarily or environmentally. By turning the WaveRider feature on, MMCloud users can automatically move a running job to an optimally sized virtual machine for each stage in the job run.
WaveRider can move jobs between On-demand and Spot instances, so if discounts are attractive, jobs can move to cheaper virtual machines as well. Spot instances have a drawback – the CSP can reclaim any Spot instance with less than two minutes warning. If the application running on the Spot instance is stateful and is not saving state periodically, then the job would have to restart from the beginning if the Spot instance were reclaimed. A job running on a Spot instance could restart multiple times if multiple Spot instance reclaim events occur during a job run. The longer the job runs, the more likely this is. A special case of WaveRider is SpotSurfer, a feature that automatically saves application state and resumes execution – without losing any intermediate progress - on a new instance. With SpotSurfer, the energy expended to complete a lengthy workflow could potentially decrease by a factor of two or three because the job is never restarted from the beginning.
Performance is maximized by running on the largest virtual machine available, but there are other metrics – power consumption and cost. Using smaller virtual machines at various stages may increase wall clock time but reduce total power consumption and cost. In principle, users can navigate this three-dimensional space to operate where their business requirements are met most efficiently, although this is not a trivial optimization problem. Plans for future MMCloud releases include the use of machine learning techniques, combined with tunable parameters, to help with this.
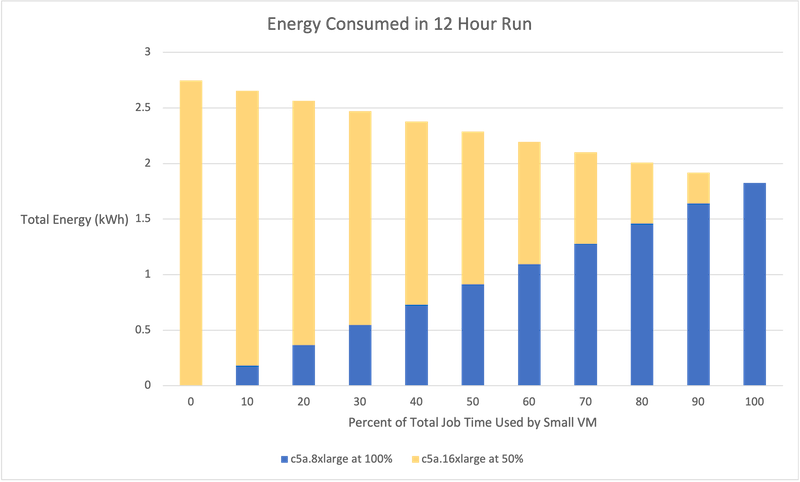
We can use a simple model to demonstrate the principle. Consider a job where the peak load requires a large virtual machine while at other times the load could be accommodated by a virtual machine with half the capacity. This is not unrealistic – the BLAST (Basic Local Alignment Search Tool) application, widely used in bioinformatics, demonstrates this behavior. Lab tests showed that, using WaveRider, a BLAST job ran 5% longer but reduced cost by over 93%. Now consider the power consumption.
The figure below shows the total power consumption for a 12-hour job that uses WaveRider to move between a large virtual machine (AWS c5a.16xlarge with 64 vCPU and 128 GB memory) and a virtual machine of half the size (AWS c5a.8xlarge with 32 vCPU and 64 GB memory). In the figure, the small instance runs at 100% capacity while the large instance runs at 50% capacity. The power figures are taken from cloudcarbonfootprint.org. The horizontal axis shows the percentage of the total job time in which the small virtual machine is running – 0% is over to the left and 100% is over to the right.
As a sample case, compare the energy consumption where the job runs on the large instance for the entire job with the case where the large instance is used for half the time. The energy consumption decreases by 17%, equivalent to increasing the gas mileage in a car from 30 mpg to 36 mpg. This is an artificial example, but it demonstrates that significant reductions in power consumption are possible if the right sized virtual machine is selected at each stage of a job run.
Accounting for Carbon Footprint
Carbon footprint is a measure of the greenhouse gases generated because of an action. Greenhouse gases include carbon dioxide, methane, nitrous oxide, and fluorinated gases. Each gas has a different heat-trapping effect. To compare actions that generate different greenhouse gases, global warming potential is measured in equivalent amounts of carbon dioxide (CO2e), that is, one ton of CO2e gas always has the same warming effect as one ton of CO2 even though the gas in question may not be carbon dioxide.
Carbon offsets provide a mechanism for reducing or removing greenhouse gases in one area to compensate for greenhouse gases generated elsewhere. For example, if you can’t buy electricity from a renewable source in your area, you can pay for the equivalent amount of electrical power to be injected into the grid from a renewable source where it is available. Or you could pay for sequestration of an equivalent quantity of carbon dioxide. The financial instrument for conducting that transaction is the carbon credit.
Morgan Stanley estimates the voluntary carbon-offset market to grow from $2 billion in 2020 to around $250 billion by 2050. Furthermore, the SEC has proposed rules that would require publicly-traded companies (over a certain size) to calculate and report their greenhouse gas emissions. This drives the need for standard ways of measuring greenhouse gas emissions for purposes such as market making, risk analysis, and corporate social responsibility reporting.
Although there are several specifications, the GHG Protocol has emerged as the de-facto standard for carbon accounting. The GHG Protocol defines three classes of emissions – labeled Scope 1, Scope 2, and Scope 3 (easily remembered as burn, buy, and beyond, respectively).
- Scope 1: direct emissions caused by facilities you own or control, for example, the gasoline you burn in your car.
- Scope 2: emissions that you cause indirectly from the energy you buy, for example, the electricity you buy to power the equipment in your data center.
- Scope 3: emissions that you cause indirectly from activities that are upstream or downstream of you (“beyond” you), such as products you buy or products that you sell and are used by others.
Scope 1 and 2 emissions are relatively straightforward to measure. In practice, Scope 3 emissions are much larger and much harder to quantify.
A CSP generates emissions in all three scopes, for example, in burning diesel fuel in a backup generator, in buying electricity to power data centers, and installing data equipment (servers, storage arrays, etc.). The cloud services you buy and use as a customer of a CSP are all sources of Scope 3 emissions from your perspective.
Translating Energy Consumption into Carbon Footprint
Translating the energy consumed by a job running on a virtual machine in a cloud data center depends on where the data center is located and how the CSP operates. The formula for converting energy consumption (measured in kWh) into operational emissions (measured in mass of CO2e) is the following:
Operational emissions (mass of CO2e) = Energy consumption (kWh) x PUE x [grid emissions factor](mass of CO2e per kWh)
where the grid emissions factor (also known as carbon intensity) is a measure of the emissions released when electrical power is generated for a data center. If the electrical power is generated entirely from renewable sources (or if legitimate carbon offsets are purchased), this factor is zero.
There are two methods for reporting carbon intensity - location-based and market-based.
The location-based method uses grid emission factors that average the emissions from all power sources within a specific geographic region over a period of time. Such calculations include a mix of energy sources, fuel types, and generation capacity. If the information is not provided by the regional power utility, the EPA’s eGRID resource is used in the US and the IEA data is used elsewhere.
The market-based method reflects the actual energy purchases made by the CSP. For example, the CSP may purchase renewable energy from outside the local region. In such a case, the market-based method would return zero as the grid emissions factor whereas the location-based would return a non-zero factor.
The big three US-based CSPs (Google Cloud, Amazon AWS, and Microsoft Azure) are all carbon neutral with respect to their energy consumption today, or will get there soon. So, while reducing power consumption is always a goal, the effect on emissions is less than it used to be. Focus is shifting to other sources of carbon footprint.
Calculating Total Carbon Footprint
The total carbon footprint is obtained by adding the “embodied emissions” to the operational emissions. Embodied emissions reflect the emissions generated because of manufacturing and transporting the IT equipment used in the data center - and are challenging to estimate. A full lifecycle assessment includes the impact of the end-of-life phase as well.
Most of the data is derived from information from manufacturers. Dell, in particular, is proactive in publishing product carbon assessments. Many of the carbon footprint calculators rely on data from the work of Benjamin Davy and the extensive database assembled by the Boavizta initiative.
As operational emissions decrease, embedded emissions become the dominant source of carbon footprint, which gives rise to complex deployment decisions: how to trade-off the reduced power consumption versus the embedded emissions generated by replacing a functioning, but older, server with the latest model.
Utilization is Key
The key to reducing carbon footprint (mainly due to embedded emissions if operational emissions are zero or close to zero in hyperscale CSPs) is managing virtual machine resources to maximize utilization. That is, size the virtual machine for the job it needs to execute and release the resources when they are no longer needed so that other users have access to the resources. If resources are idle but locked up (that is, not available to other users), the CSP is forced to deploy additional servers and incur additional carbon footprint as a result. Similarly, if servers are underutilized, emissions are needlessly incurred because more servers are deployed (and drawing power) than are required.
Conclusion
Carbon footprint is an important focus for public companies, many of whom have a target year to reach carbon neutrality. Pre-IPO companies are expected to have clear ESG disclosures. IT can be a significant generator of carbon emissions, although by moving IT services to the cloud, companies can take advantage of the substantial efficiencies that are engineered into cloud operations. All the hyperscale CSPs have made pledges to reach “net zero” operations. Both Amazon and Azure have the goal of their matching annual global energy use with renewable energy purchases by 2025. Google goes a step further with a goal of meeting all electricity demand with carbon-free energy every hour of every day in every region by 2030.
Today, MMCloud users can take advantage of all the progress Amazon AWS and Google Cloud have made towards carbon neutrality and add an extra optimization: use the virtual machine that fits the job resource utilization demands at every stage – no more over-provisioning “just to be safe.” This is the core philosophy behind serverless architectures – only use the resources you need, when you need them, and for as long as you need them. In a way, it is like turning the lights off when no-one is in the room – you save energy and no sacrifices are required.